Serialize: How I Solved the Context Window Problem for Long-Running Agent Projects
AI agents are great at focused tasks. Give Claude a well-scoped problem and it’ll knock it out. But what happens when the project is bigger than what fits in a single context window?
This post documents my journey from problem to solution, including the dead ends and the insight that made everything click.
The Problem
I wanted Aqua agents to handle multi-day projects. Think: “Build a full-stack app with authentication, API, frontend, and tests.” This naturally breaks into 10-20 tasks, and by the time an agent finishes task 5, its context window is packed with implementation details from tasks 1-4.
The agent starts making mistakes. It forgets architectural decisions. It repeats work. Eventually, you have to manually intervene.
The core tension: Agents need context to make good decisions, but accumulating context eventually overwhelms them.
First Attempt: Manual Compaction
Claude Code has a /compact command that summarizes the conversation and frees up context. My first thought: just tell agents to run /compact periodically.
aqua add "Build API" -p 10
aqua add "Run /compact" -p 9 # Manual checkpoint
aqua add "Write tests" -p 8
This works, sort of. But it’s brittle:
- Agents might forget to run
/compact - The summary is unpredictable—important details might get lost
- There’s no guarantee the agent remembers where it was in the workflow
I needed something more structured.
The Serialize Idea
What if I could explicitly plan for context management? Instead of hoping the agent remembers to compact, I build checkpoints into the task sequence:
aqua add "Set up project structure"
aqua add "Create data models"
aqua add "Build API endpoints"
aqua add "Write tests"
aqua serialize # Insert checkpoints between tasks
The serialize command would:
- Topologically sort tasks (respecting dependencies)
- Insert checkpoint tasks between work tasks
- Create a linear chain so tasks execute sequentially
Result:
1. Set up project structure
2. [Checkpoint]
3. Create data models
4. [Checkpoint]
5. Build API endpoints
6. [Checkpoint]
7. Write tests
Each checkpoint would be a pause for context management. But how should checkpoints actually work?
Dead End #1: Checkpoints That Tell Agents to /compact
My first implementation had checkpoints instruct the agent:
Checkpoint: Compact Your Context
Run these commands:
1. /compact
2. aqua refresh
3. aqua done
4. aqua claim
The idea: agent compacts, then aqua refresh restores essential context from the database (previous task summary, upcoming tasks, agent identity).
Problem: After /compact, the agent retains some compressed context, but it’s unpredictable what survives. The agent might remember it was in a workflow, or it might not. And context recovery depends on the agent faithfully following the checkpoint instructions.
This felt fragile.
Dead End #2: The /clear + Hooks Approach
Then I thought: what if I use /clear instead of /compact? Complete context wipe, fresh start. The database becomes the single source of truth.
Claude Code has hooks that fire on events. I discovered there’s a SessionStart hook with a “clear” matcher that fires after /clear:
{
"hooks": {
"SessionStart": [
{
"matcher": "clear",
"hooks": [
{
"type": "command",
"command": "aqua refresh"
}
]
}
]
}
}
In theory: agent runs /clear, hook fires, aqua refresh runs automatically, context restored from DB.
Problem: After /clear, Claude Code waits for user input. There’s no automatic continuation. The hook runs, but then the agent just sits there with no prompt to act on.
This approach might work in some specialized setup, but not in the general case. Back to the drawing board.
The Insight: Agents Should Exit, Aqua Should Respawn
I was stuck thinking about how to manage context within an agent session. The breakthrough came from flipping the model:
What if the agent just exits at checkpoints, and Aqua spawns a fresh one?
Think about it:
- Fresh process = fresh context window (200k tokens available)
- No reliance on
/compactor/clearworking correctly - No hooks needed
- Aqua becomes the orchestrator, not a plugin
The checkpoint becomes a signal for the agent to stop. Aqua watches for the exit, checks if there’s more work, and spawns a new agent if needed.
The Final Design
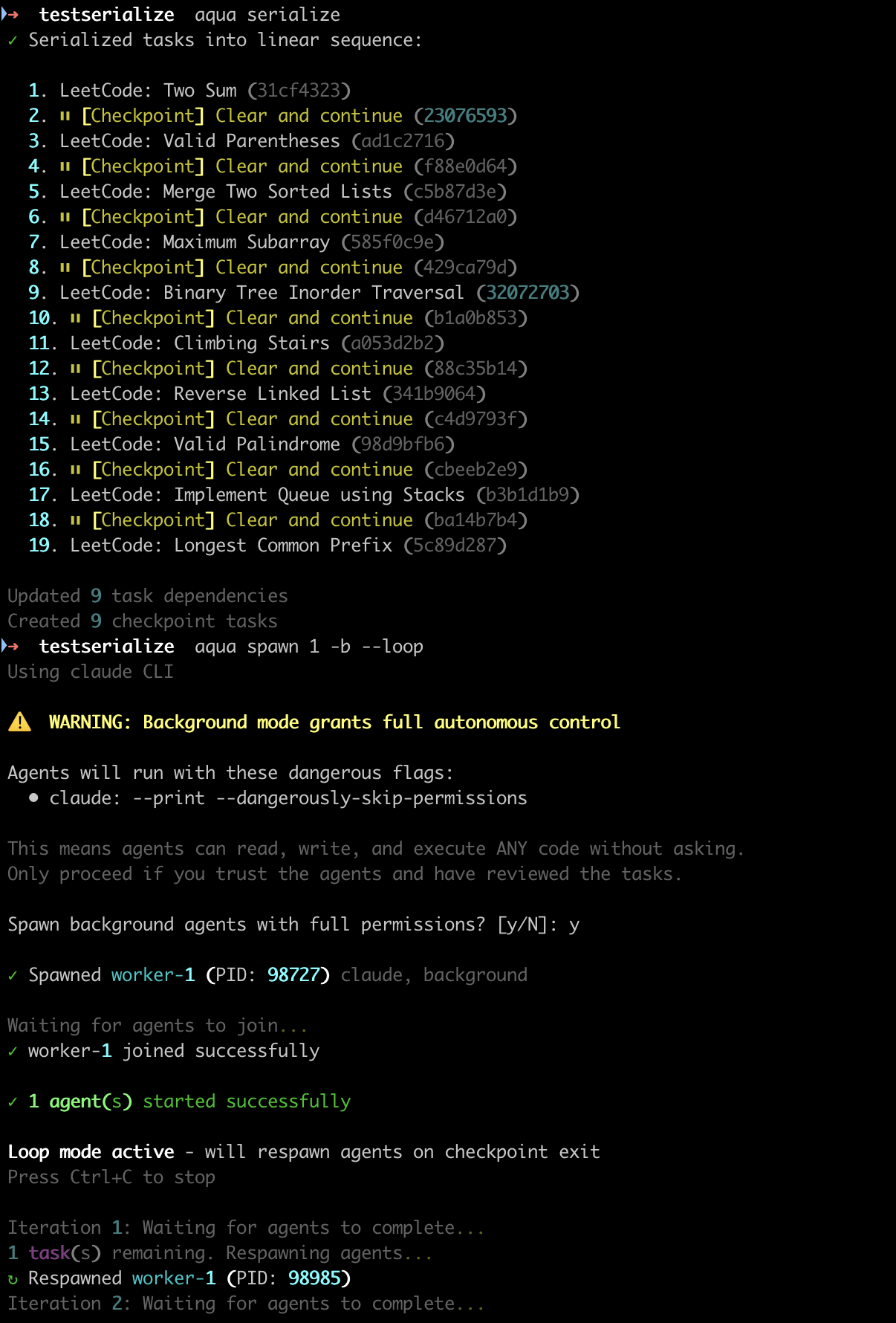
1. Serialize Creates the Plan
aqua serialize
This takes your pending tasks, respects their dependencies via topological sort, and inserts checkpoint tasks:
✓ Serialized tasks into linear sequence:
1. Set up project structure (abc123)
2. ⏸ [Checkpoint] Clear and continue (def456)
3. Create data models (ghi789)
4. ⏸ [Checkpoint] Clear and continue (jkl012)
5. Build API endpoints (mno345)
...
2. Checkpoints Tell Agents to Exit
When an agent claims a checkpoint, they see:
╭─────────────── ⏸ Checkpoint ───────────────╮
│ Checkpoint Reached │
│ │
│ This is a context checkpoint. Run: │
│ aqua done │
│ │
│ Then exit this session. Aqua will respawn │
│ a fresh agent with full context restored. │
╰─────────────────────────────────────────────╯
The agent runs aqua done (marking the checkpoint complete) and exits.
3. Loop Mode Respawns Agents
aqua spawn 1 -b --loop
The --loop flag tells Aqua to watch for agent exits and respawn:
Loop mode active - will respawn agents on checkpoint exit
Press Ctrl+C to stop
Iteration 1: Waiting for agents to complete...
↻ Respawned worker-1 (PID: 12345)
Iteration 2: Waiting for agents to complete...
↻ Respawned worker-1 (PID: 12346)
...
✓ All tasks complete! Exiting loop.
Each respawn gets a fresh context window. The agent’s first action is aqua refresh, which pulls context from the database:
You are: worker-1 ★ LEADER
Previous Task Completed:
"Create data models"
Summary: Added User, Post, and Comment models with SQLAlchemy...
Coming Up Next:
1. Build API endpoints
2. Write tests
3. Deploy to staging
4. Context Survives in SQLite
The key insight: context lives in the database, not in the agent’s memory.
When an agent completes a task, they provide a summary:
aqua done --summary "Created User model with email validation, Post model with foreign key to User..."
This summary is stored in task.result. When the next agent runs aqua refresh, they see this summary plus the upcoming tasks. They have all the context they need to continue, even though they’re a completely fresh process.
The Complete Flow
User/Leader Agent:
│
├─→ Plans tasks with dependencies
│ aqua add "Task A" -p 10
│ aqua add "Task B" --after "Task A"
│ aqua add "Task C" --after "Task B"
│
├─→ Serializes with checkpoints
│ aqua serialize
│
└─→ Starts loop mode
aqua spawn 1 -b --loop
│
│ ┌─────────────────────────────┐
│ │ Iteration 1 │
│ │ Worker claims Task A │
│ │ Worker completes Task A │
│ │ Worker claims Checkpoint │
│ │ Worker runs: aqua done │
│ │ Worker exits │
│ └─────────────────────────────┘
│
├─→ Aqua detects exit, checks pending tasks
│ Tasks remaining: 4
│
│ ┌─────────────────────────────┐
│ │ Iteration 2 │
│ │ Fresh worker spawns │
│ │ Worker runs: aqua refresh │
│ │ Worker sees: Task A done │
│ │ Worker claims Task B │
│ │ Worker completes Task B │
│ │ Worker claims Checkpoint │
│ │ Worker exits │
│ └─────────────────────────────┘
│
└─→ ... continues until all done
Why This Works
-
Fresh context per task batch: Each spawned agent has a full 200k token context window. No accumulation, no degradation.
-
Database is the source of truth: Task summaries, agent identity, upcoming work—all in SQLite. Survives any context operation.
-
Aqua is the orchestrator: The agent doesn’t need to remember to compact or manage its own lifecycle. Aqua handles it.
-
Works with existing features:
--loopcomposes with roles, multiple agent types, worktrees—everything inaqua spawn. -
Leader can exit: Once you run
aqua spawn -b --loop, the background process handles everything. The leader agent (or you) can exit.
Usage Examples
Basic serialization
# Plan work
aqua add "Set up project" -p 10
aqua add "Build feature X" -p 9
aqua add "Write tests" -p 8
# Serialize and run
aqua serialize
aqua spawn 1 -b --loop
With roles
aqua add "Review architecture" -t review -p 10
aqua add "Build API" -t backend -p 9
aqua add "Build UI" -t frontend -p 8
aqua add "Integration tests" -t testing -p 7
aqua serialize
aqua spawn 4 -b --loop --roles reviewer,backend,frontend,testing
Preview without executing
aqua serialize --dry-run
Checkpoint every 2 tasks
aqua serialize --every 2
Single task with checkpoint
aqua add "Complex refactoring" --checkpoint
What’s Next
This feature opens up interesting possibilities:
-
Smart checkpoint placement: Instead of fixed intervals, detect when context is getting full and insert checkpoints dynamically.
-
Parallel serialization: Multiple workers each with their own serialized sub-chains, merging at sync points.
-
Checkpoint summaries: Auto-generate better task summaries using the conversation history before exit.
-
Resume from failure: If an agent crashes mid-task, the loop can detect and retry.
Install/Upgrade
pip install --upgrade aqua-coord
The journey from “agents forget things” to “Aqua orchestrates fresh agents” took several wrong turns. But the final design is simpler and more robust than any of the hook-based approaches. Sometimes the right abstraction isn’t making the thing work better—it’s changing what the thing is.
| Previous: Agent Roles: Spawn Specialized Teams That Self-Organize | All Posts |